
How AI Image Generators Actually Work: (Not Collage, Not Magic)

Note: This article presents the key concepts from my technical deep-dive in accessible language. For the full research with academic citations and detailed analysis, see: How AI Actually Creates Images: What the Research Reveals
Type "a dragon eating ice cream on Mars" into Midjourney or DALL-E, and seconds later you'll have a photorealistic image of exactly that. It's remarkable, it feels like magic, and it's sparked fierce debates about creativity, copyright, and whether AI is a revolutionary tool or an elaborate theft machine.
So what's actually happening when AI generates an image? Is it creating something genuinely new, or just remixing stolen art? The answer turns out to be more nuanced—and more interesting—than the heated arguments on either side suggest.
This guide breaks down what recent scientific research tells us about how these systems actually work, what they can and can't do, and what remains genuinely uncertain. You'll understand:
The core mechanism: How models transform random TV static into coherent images through learned patterns (not by retrieving stored image pieces)
The memorization problem: Why these systems sometimes reproduce training images almost exactly—and why this appears to be the exception rather than the rule
The copyright minefield: What the Getty Images lawsuit actually decided (and more importantly, what it left unresolved)
The honest complications: Why neither "it's just a tool" nor "it's just theft" captures the full reality
What you won't find here: Technical jargon, mathematical formulas, or oversimplified takes that ignore inconvenient evidence. Instead, you'll get clear explanations using everyday analogies—think jazz musicians, Polaroid cameras, and language translators—that help you understand what's actually happening under the hood.
The short version if you're pressed for time: AI image generators learn patterns from millions of training images, then apply those patterns to transform random noise into new images. This is genuinely generative—they're not cutting and pasting from a database—but everything they know comes from existing art. Sometimes (rarely) they memorize and reproduce near-exact copies of training images, especially ones they saw repeatedly. Whether any of this is legal or ethical remains hotly contested, with courts still working through questions that existing copyright law wasn't designed to answer.
Fair warning: If you're looking for a simple answer that confirms what you already believe, you might be disappointed. The research shows both AI advocates and critics are partly right and partly wrong. The truth is messier than either side wants to admit.
Ready to understand what's really going on? Let's dive in.
The bottom line up front: AI image generators like Midjourney, Stable Diffusion, and DALL-E create pictures by progressively removing noise from random static—kind of like slowly focusing a blurry photograph. They've learned how to do this by studying millions of images, but they don't typically copy-paste from those images. However, they can memorize and reproduce specific images under certain conditions, which is where things get legally messy.
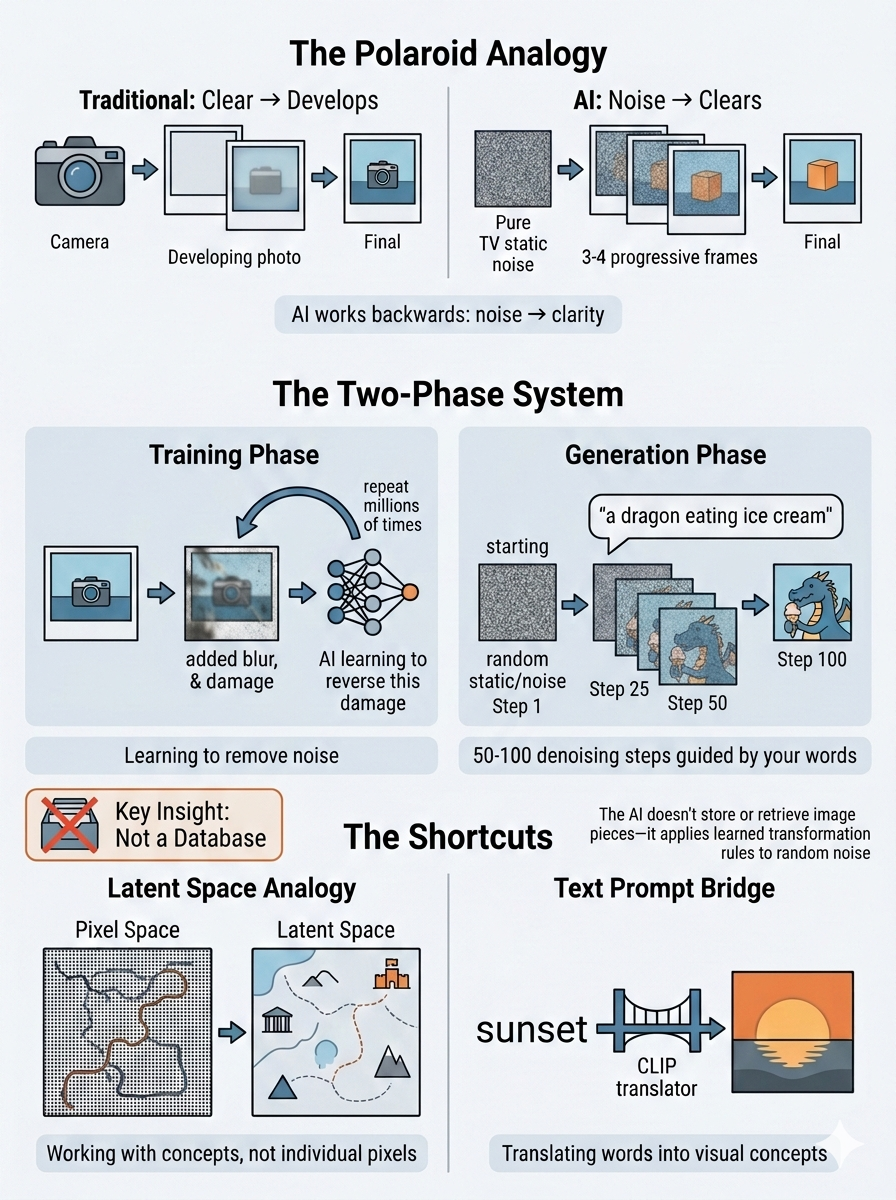
Part 1: The Basic Process—Noise to Image
Think of it like developing a Polaroid in reverse
Remember those old Polaroid cameras where you'd take a photo and watch it slowly appear as the chemicals developed? AI image generation works almost exactly backwards:
Traditional photo development: Camera captures image → Chemicals gradually reveal it → You see the final picture
AI image generation: Start with pure noise → Gradually remove noise → Final picture appears
The two-phase training system
Phase 1: Learning (Training)
Imagine teaching someone to restore old, damaged photographs:
You take a perfect photo
You deliberately damage it (add scratches, blur it, fade it)
You ask them to fix it
You do this millions of times until they become an expert at restoration
That's basically how the AI learns. Except instead of damage, they add mathematical "noise" (think TV static), and the AI learns to remove it.
Phase 2: Creating (Generation)
Now when you want a new image:
The AI starts with pure random static (like a TV with no signal)
It applies everything it learned about "de-noising"
But this time, you guide it with words: "a dragon eating ice cream"
Over 50-100 tiny steps, it gradually reveals an image matching your description
The key insight: The AI isn't reaching into a database and pulling out dragon parts and ice cream parts. It's applying learned transformation rules to random noise. The randomness means every generation is unique—you couldn't generate the same image twice even if you tried (unless you deliberately use the same random "seed").
The latent space shortcut
Most modern systems don't work directly with pixels—that would be like trying to edit a 4K movie frame-by-frame. Instead, they work in "latent space," which is essentially a compressed, abstract representation.
Analogy: Think of it like this:
Pixel space = Giving someone directions as "go 3 feet forward, turn 2 degrees left, go 5 feet forward..."
Latent space = Giving someone directions as "head toward downtown, turn at the big oak tree..."
The second way captures the meaningful information while ignoring irrelevant details. Latent space focuses on concepts and patterns rather than individual pixels, making the process thousands of times faster.
How text prompts work
The system uses something called CLIP (or similar models) that creates a bridge between language and images.
Analogy: Imagine a bilingual translator who grew up speaking both English and "Image" fluently. When you say "sunset," they know exactly what that looks like in Image-language because they've seen 400 million examples of words paired with pictures.
Your text prompt gets translated into this shared language, which then guides each denoising step toward images that match your description.

Part 2: The Memorization Problem
When learning becomes copying
Here's where the simple story gets complicated. In 2023, researchers from Google and DeepMind discovered something important: these models can and do memorize specific training images.
They ran a systematic test:
Generated thousands of images with targeted prompts
Compared them to the training data
Found over 1,000 near-perfect copies of training images
The Ann Graham Lotz example: When prompted with her name, Stable Diffusion generated an image nearly identical to a specific training photo—so close that the mathematical difference was essentially zero.
The frequency factor
The memorization wasn't random. Images that appeared many times in the training data were far more likely to be memorized than images that appeared once.
Analogy:
See a stranger's face once on the street → You probably can't draw them from memory
See the same face in 50 different photos → You could probably sketch a pretty accurate portrait
See the Mona Lisa 1,000 times → You might reproduce it almost perfectly
But most generations are genuinely new
The same research showed that most outputs aren't memorized copies. When they asked for "a photo of Barack Obama," the AI generated a clearly recognizable Obama—but it wasn't a copy of any specific training photo. It had learned what Obama looks like and synthesized something new.
Current understanding: Memorization appears to be the exception rather than the rule, but it's a real exception that happens under identifiable conditions (high training frequency, specific prompting).

Part 3: The Training Data Question
The scale is staggering
Stable Diffusion 2 was trained on billions of image-text pairs scraped from the internet via the LAION dataset.
For perspective: If you looked at one image per second, 24/7, it would take you about 95 years to see 3 billion images.
But here's a surprising finding: researchers trained a comparable model using only 70 million Creative Commons-licensed images (about 3% of the full dataset). This suggests quality and curation matter enormously—though 70 million is still a massive corpus.
The bias problem
The models don't just learn what things look like—they learn statistical patterns, including societal biases.
Example from research: When prompted with "a photo of a programmer," Stable Diffusion generated almost exclusively male programmers, dramatically underrepresenting women.
This isn't a bug in the code—it's the model accurately reflecting bias in the training data (which itself reflects bias in internet imagery). It's like if you learned everything you knew about programmers from 1960s advertisements—you'd also think they were all men.
One copyright-conscious approach
Some researchers tried a clever workaround called "synthetic captioning":
Take Creative Commons-licensed images (which are legal to use)
Use one AI (BLIP-2) to write descriptions of those images
Use those AI-written descriptions to train a different AI (the image generator)
This approach—they call it "telephoning"—produced a model competitive with Stable Diffusion 2 while using only legally-licensed images.
Analogy: It's like learning to cook by:
Reading someone else's description of a dish (rather than tasting it directly)
Using those descriptions to learn cooking principles
Creating your own recipes based on those principles

Part 4: The Getty Images Lawsuit
What actually happened in court
Getty Images sued Stability AI for using their copyrighted images in training. The November 2025 UK ruling was more procedural than substantive:
Copyright claims: Dismissed—but not because the court ruled "training on copyrighted data is legal." Getty abandoned most claims before trial because they couldn't prove that specific acts of copying occurred within UK jurisdiction with the evidence they had.
Trademark claims: Partial victory for Getty. The court found that when Stable Diffusion occasionally generated images with Getty's watermark visible, that was trademark infringement—and crucially, the responsibility lies with the model provider, not the user.
What wasn't resolved:
Whether training on copyrighted material is legal in general
Whether generated outputs are "derivative works"
How fair use applies to statistical learning
Anything definitive for other jurisdictions
Getty's own statement afterward: They plan to pursue the case in other venues and urged governments to establish clearer transparency rules—essentially admitting the legal framework isn't settled.

Part 5: Detection and Forensics
Can you tell if an image is AI-generated?
Yes, often—but it requires technical analysis.
Spectral signatures: AI-generated images leave subtle "fingerprints" in their frequency patterns (visible through Fourier analysis with high-pass filters). Think of it like how you can sometimes tell a photocopy from an original—there are artifacts invisible to casual viewing but detectable with the right tools.
These signatures survive mild JPEG compression and differ from normal compression artifacts.
Can artists prove their work was used in training?
A 2025 research project developed "Copyrighted Data Identification" (CDI) that works at the dataset level rather than individual images.
The innovation: Instead of trying to prove one specific image was used (very difficult), you can test with 70+ images from your portfolio. The statistical patterns can identify with 99%+ confidence whether that collection was in the training data.
Analogy: It's like identifying a specific dialect. One word might not tell you much, but 70 words together reveal clear patterns about where someone learned to speak.
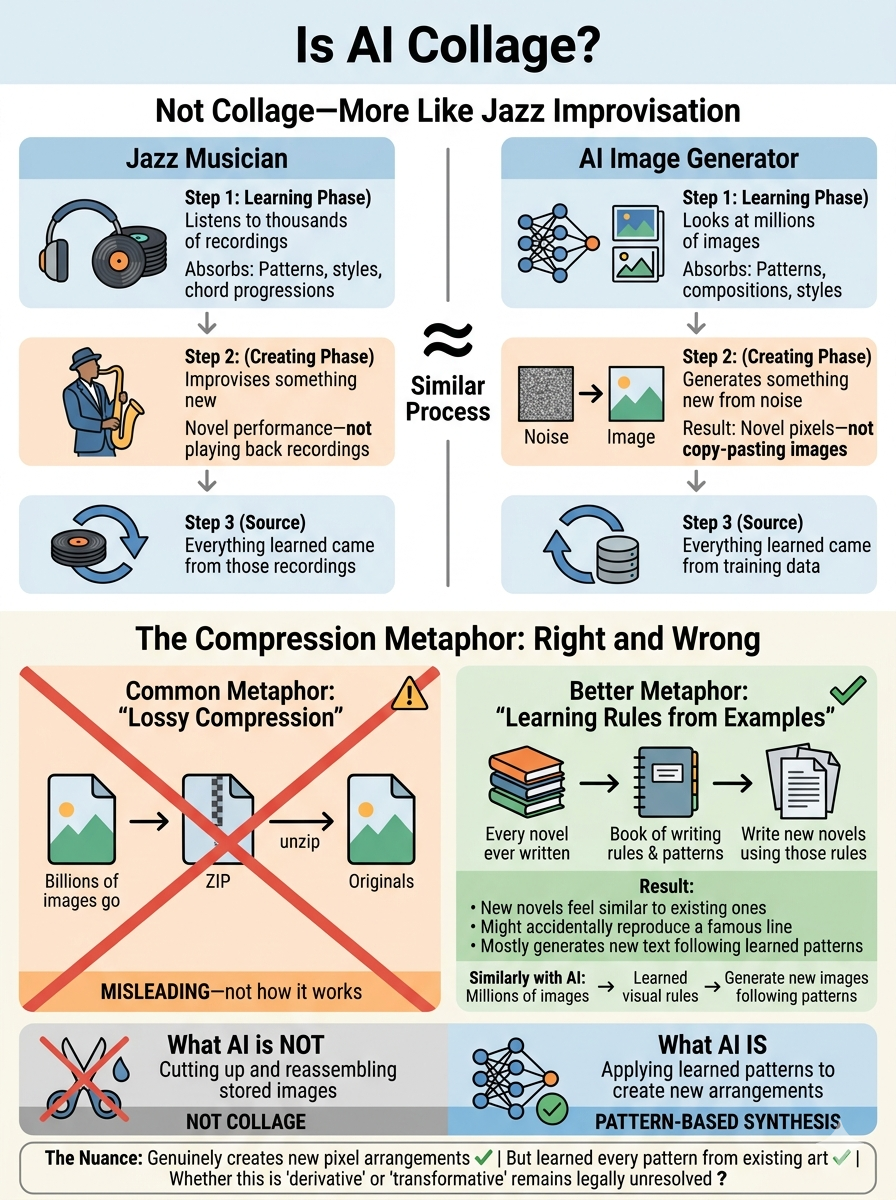
Part 6: So Is It Collage or Not?
The musician analogy
The best comparison is probably a jazz musician:
What a jazz musician does:
Listens to thousands of recordings (learning)
Absorbs patterns, styles, chord progressions, rhythmic structures
Improvises something new (generating)
Their improvisation is genuinely novel—not playing back recordings
But everything they know came from what they heard
What AI does:
"Looks at" millions of images (learning)
Absorbs patterns, compositions, styles, visual structures
Generates something new from noise (creating)
The output is genuinely novel pixel arrangements—not copying-pasting images
But everything it knows came from training data
The "lossy compression" metaphor
You might hear AI described as "lossy compression of the training set." This captures something true but also misleads:
What's accurate:
All the model's knowledge comes from compressing billions of images into mathematical parameters
You can sometimes extract training data back out (the memorization problem)
What's misleading:
It's not like a ZIP file that decompresses to originals
It's more like learning general rules from specific examples
Normal generation synthesizes from learned patterns, not retrieval
Better analogy: It's like compressing "every novel ever written" into a book of writing rules and common patterns. You could use those rules to write new novels that feel similar to existing ones—and occasionally you might accidentally reproduce a famous passage—but mostly you're generating new text following learned patterns.
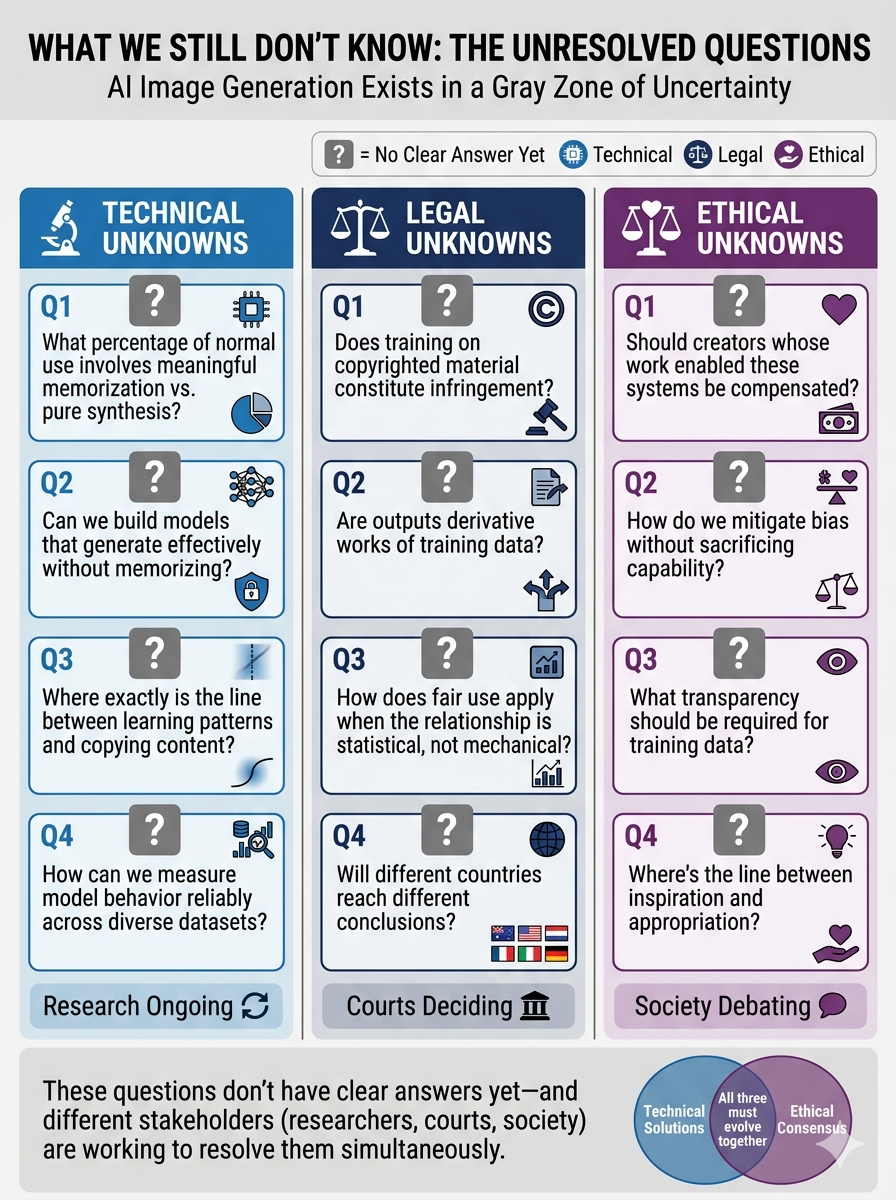
The Unresolved Questions
Technical unknowns:
What percentage of normal use involves meaningful memorization vs. pure synthesis?
Can we build models that generate effectively without memorizing?
Where exactly is the line between learning patterns and copying content?
Legal unknowns:
Does training on copyrighted material constitute infringement?
Are outputs derivative works of training data?
How does fair use apply when the relationship is statistical, not mechanical?
Will different countries reach different conclusions?
Ethical unknowns:
Should creators whose work enabled these systems be compensated?
How do we mitigate bias without sacrificing capability?
What transparency should be required for training data?
Where's the line between inspiration and appropriation?
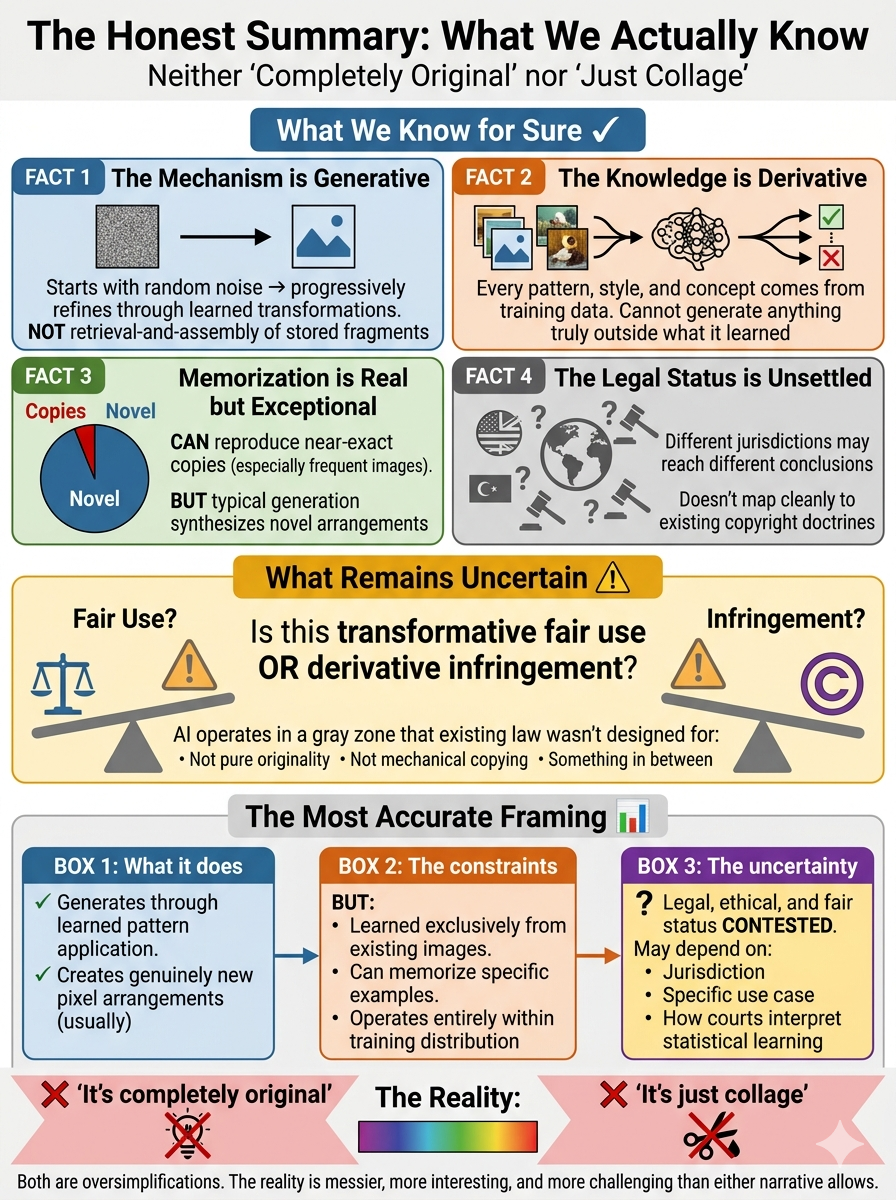
The Honest Summary
What we know:
The mechanism is generative: AI starts with random noise and progressively refines it into coherent images through learned transformations. This is not retrieval-and-assembly of stored image fragments.
The knowledge is derivative: Every pattern, style, and visual concept comes from training data—the system cannot generate anything truly outside what it learned.
Memorization is real but exceptional: Models can reproduce near-exact copies of training images (especially frequently-seen ones), but typical generation appears to synthesize novel arrangements.
The legal status is unsettled: Different jurisdictions may reach different conclusions. The relationship between training data and outputs doesn't map cleanly to existing copyright doctrines designed for human creators.
What remains uncertain:
Whether this constitutes transformative fair use or derivative infringement. The models operate in a gray zone that existing law wasn't designed to address—they're neither pure originality nor mechanical copying.
The most accurate framing:
Diffusion models generate through learned pattern application—genuinely creating new pixel arrangements in most cases. However, they learned exclusively from existing images, can memorize specific examples, and operate entirely within their training distribution. Whether this is legal, ethical, and fair remains contested and may depend on jurisdiction, specific use case, and how courts ultimately interpret statistical learning relationships to source material.
Both "it's completely original" and "it's just collage" are oversimplifications. The reality is messier, more interesting, and more challenging than either narrative allows.
Key Terms & Definitions
Diffusion models – The type of AI system used by modern image generators like Stable Diffusion, Midjourney, and DALL-E. They work by learning to remove noise from images, then reversing this process to generate new images from random noise.
Training data – The millions or billions of images the AI "looks at" during its learning phase. Like a student studying from textbooks, the AI learns patterns, styles, and visual concepts from this dataset.
Latent space – A compressed, abstract representation of images that AI works with internally. Think of it like working with a simplified map instead of examining every grain of sand on a beach—it captures what matters while being much faster to process.
CLIP (Contrastive Language-Image Pretraining) – The AI system that connects text prompts to images. It learned from 400 million text-image pairs and acts like a translator between the words you type and the visual concepts the generator understands.
Denoising – The process of removing noise (random static) from an image. AI image generators learn to denoise, then use this ability backwards—starting with pure noise and progressively removing it to reveal a coherent image.
Memorization – When an AI reproduces a near-exact copy of a training image instead of creating something new. This happens particularly with images the AI saw many times during training, but research shows it's the exception rather than the rule.
Synthetic captioning – A training method where one AI writes descriptions of images, then those descriptions are used to train a different AI. Think of it like learning to cook from someone's written description of a dish rather than tasting it yourself.
Fair use – A legal doctrine (mainly in US law) that allows limited use of copyrighted material without permission under certain circumstances, such as for education, criticism, or transformative purposes. Whether AI training qualifies is currently unresolved.
Derivative work – A legal term for creative work that's based on or derived from existing copyrighted material. Whether AI-generated images are derivative works of their training data is one of the key unresolved legal questions.
Spectral signatures – Mathematical patterns in the frequency data of images that can reveal whether an image was AI-generated. These are invisible to the human eye but detectable through technical analysis (like Fourier transforms with high-pass filters).
CDI (Copyrighted Data Identification) – A research method that can prove whether an artist's work was used in AI training by analyzing 70+ images from their portfolio statistically, rather than trying to prove a single image was used.
Statistical learning – How AI systems learn by finding patterns and probabilities across large datasets, rather than memorizing specific examples. It's closer to how humans learn general principles from many examples than to how a photocopier duplicates an exact image.
Novel synthesis – When AI generates genuinely new pixel arrangements that don't exist in any training image, by combining and applying learned patterns in new ways—like how a jazz musician improvises using learned musical patterns.
Technical Terms (For Reference)
If you encounter these in more technical discussions:
Neural network – The mathematical structure that powers AI systems, loosely inspired by how neurons in the brain connect and process information.
Parameters – The mathematical values the AI adjusts during training. Modern image generators have billions of parameters that encode all their learned knowledge.
Embedding – A mathematical representation that captures the meaning or features of something (like text or images) in a way computers can process.
Iterative process – A step-by-step process that repeats many times. AI image generation typically takes 50-100 iterative steps to transform noise into a final image.
Gaussian noise – A specific type of random noise (looks like TV static) that follows a particular mathematical pattern. This is what AI image generators start with.
Note: You don't need to memorize these terms to understand the article—it's written to be accessible without technical background. This glossary is here if you want to go deeper or encounter these terms elsewhere.