
How AI Actually Creates Images: What the Research Reveals
20 min read
A deep dive into the science behind AI image generators like Stable Diffusion, Midjourney, and DALL-E
Note: For a shorter/simpler version that includes more reflection about the imagery and comparisons to standard prior knowledge, see: How AI Image Generators Actually Work: (Not Collage, Not Magic).
I am not claiming to fully understand the math or approaches in the studies presented. I am trying to understand the process better. I provided source material to Claude and had it synthesize and explain it for me. Through our discussions, questions, and clarifications, this article was written. Some of the formulas may be incorrect. If you find errors, please let me know.
Introduction

Image created using Midjourney
Type "a dragon eating ice cream on Mars" into an AI image generator, and within seconds, you'll have a photorealistic rendering of exactly that—something that's never existed before. But how does this actually work? And perhaps more importantly: is AI image generation essentially a sophisticated form of digital collage, reassembling pieces of existing artwork?
To answer these questions, I examined recent academic research on generative AI, including papers from computer vision conferences, security symposiums, and legal analyses. What emerged is a picture (pun intended) far more nuanced than most public discourse suggests.
The short answer: AI image generation typically operates through learned statistical transformations of random noise—a generative process rather than retrieval and assembly. However, research shows these models can and do memorize training examples under certain conditions, particularly when those examples appear frequently in training data. The truth resists simple categorization.
Part I: The Technical Reality—From Noise to Image
The Diffusion Process: Transforming Chaos into Coherence
Modern AI image generators like Stable Diffusion, Midjourney, and DALL-E are built on diffusion models (though specific product implementations may vary in their architectures and approaches). The fundamental mechanism is elegantly simple, though mathematically sophisticated.
As Carlini et al. explain in their 2023 security analysis, "Denoising Diffusion Probabilistic Models (DDPMs) are conceptually simple: they are nothing more than image denoisers."[^1] While this is somewhat simplified—the models do more than basic denoising in practice—it captures the core training objective. Here's how it works:
The Training Phase (Learning to Remove Noise):
The model learns by taking clean images and progressively adding noise to them. Mathematically, given a clean image x, the system samples a time-step t and Gaussian noise ε to produce a noised image using the formula: x' = √(aₜ)x + √(1-aₜ)ε, where aₜ is a decaying parameter.[^1]
The neural network then trains to predict and remove that noise, learning the reverse transformation through millions of examples.

The Generation Phase (Creating from Noise):
To generate a new image, the process reverses. The system starts with pure random noise—what Kabir et al. describe as "a substantial amount of random noise, akin to the colorized rendition of the white noise observed on a screen lacking signal."[^2]
Through an iterative process, typically 50-100 steps, the model progressively denoises this random static. As Carlini notes, "Despite being trained with this simple denoising objective, diffusion models can generate high-quality images by applying the diffusion model fθ to denoise a completely random 'image.'"[^1]
The denoising follows the iterative rule: zₜ₋₁ = fθ(zₜ,t) + σₜN(0,I), where each step removes some noise while adding slight controlled randomness, gradually revealing structure and detail.[^1]
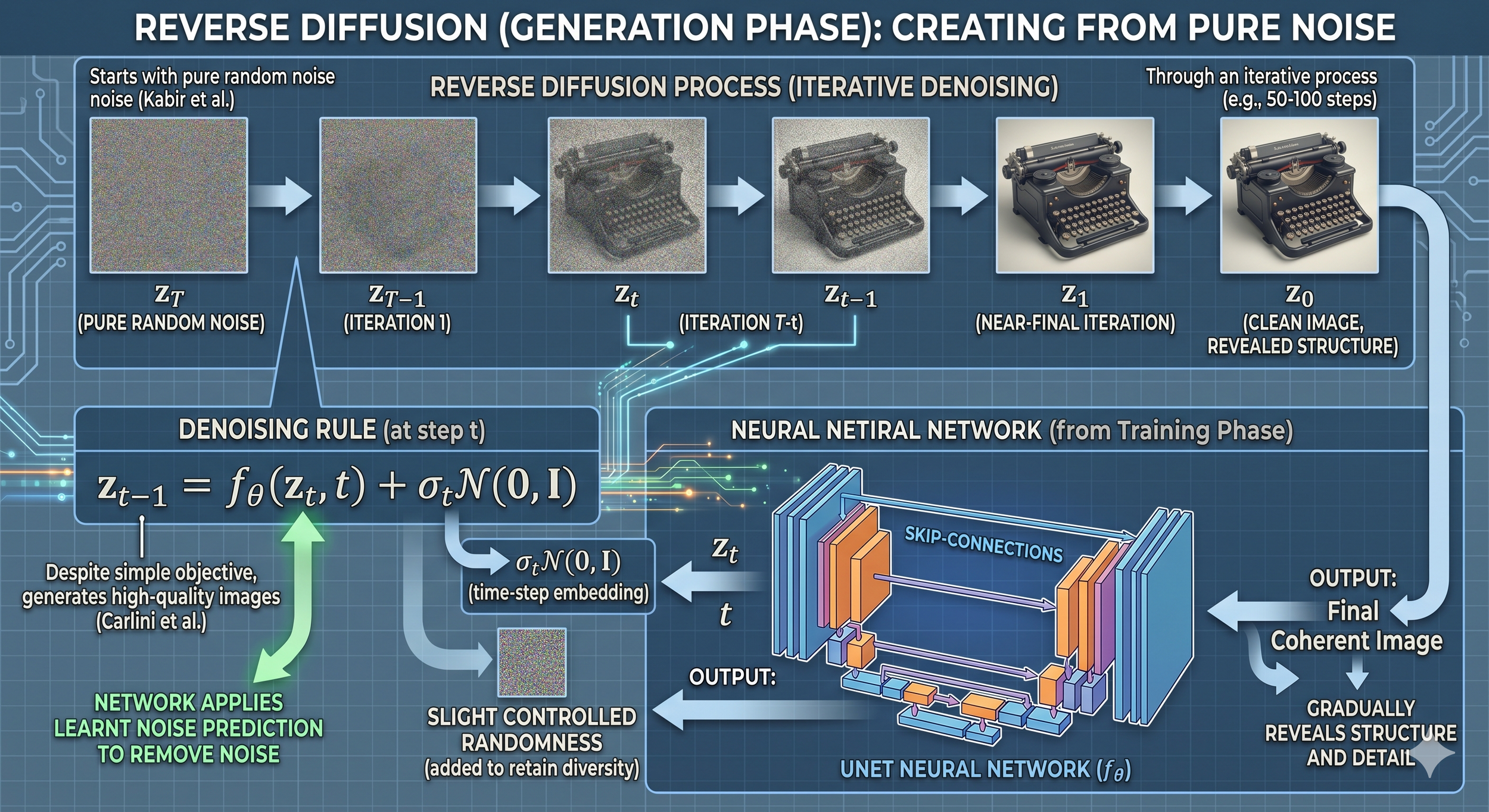
What this typically means: In most generations, the model doesn't retrieve stored images or image fragments. It applies learned transformations to random noise, guided by patterns extracted from training data. (Memorization, which we'll discuss later, represents an important exception to this general pattern.)
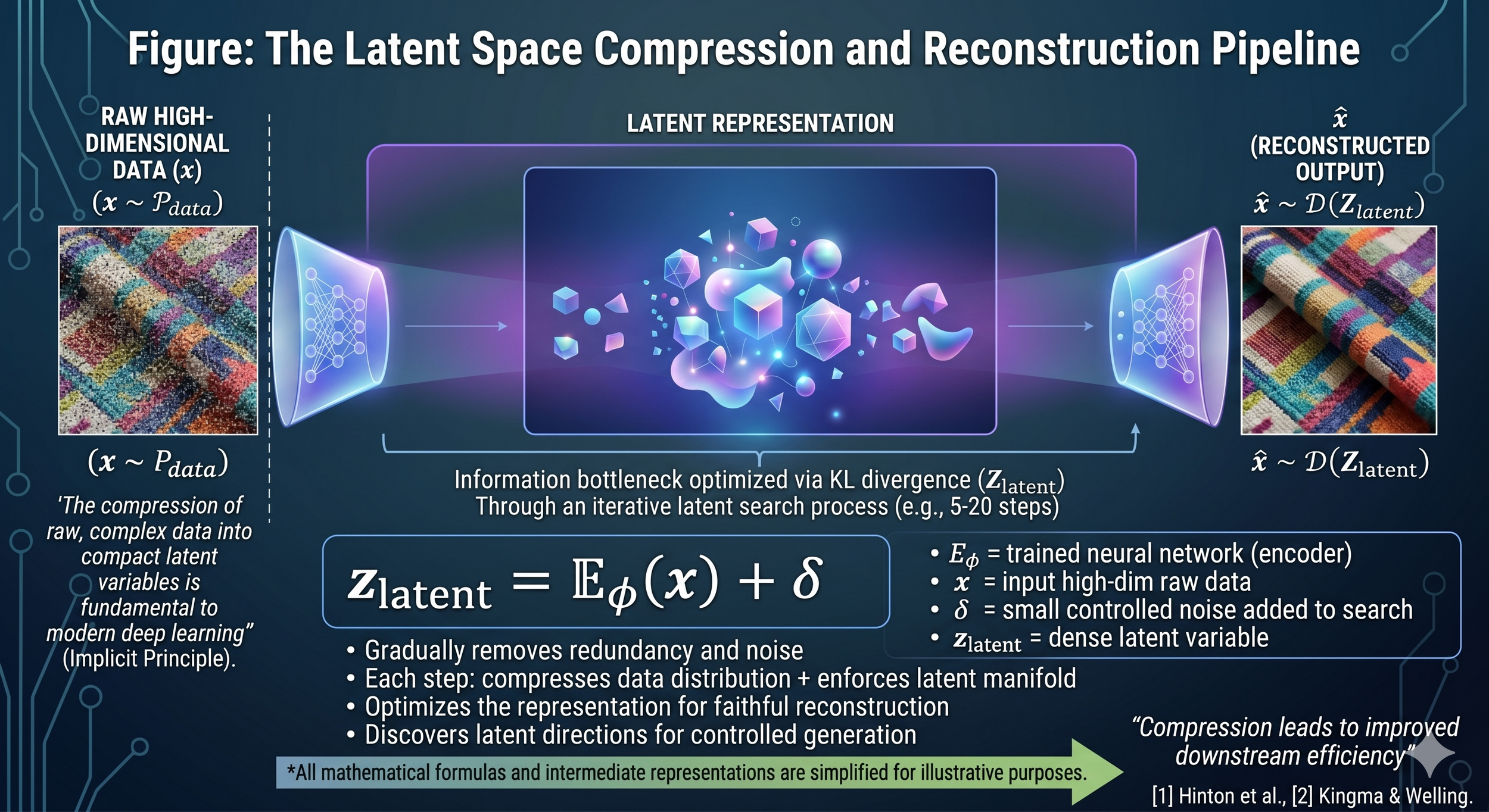
Latent Space: The Efficiency Innovation
Many modern diffusion models—particularly latent diffusion models like Stable Diffusion—don't work directly on pixels, which would be computationally prohibitive. Instead, they operate in what's called "latent space," a compressed representation of images.
Kabir et al. explain this innovation: "By using skilled perceptual compression models, which are made up of an encoder (E) and a decoder (D), it was able to access a latent space that was effective and had fewer dimensions. In this latent space, intricate details that are invisible to human senses, particularly those pertaining to high frequencies, are condensed and removed."[^2]
This approach offers multiple advantages. As the researchers note, "In contrast to the high-dimensional pixel space, this alternative space is better suited for likelihood-based generative models. This is because these models can now prioritize the significant semantic aspects of the data and train in a lower-dimensional space, which is computationally more efficient."[^2]
In practical terms: the system learns patterns and semantic meaning rather than individual pixels, making it orders of magnitude faster while preserving what actually matters for image quality.
Text Conditioning: Bridging Language and Vision
How does the system know what to generate? Through text conditioning, typically enabled by models like CLIP (Contrastive Language-Image Pretraining), though specific implementations vary.
Kabir et al. describe CLIP as "a versatile image-text model that has been trained on a vast dataset of 400 million text-image pairs sourced from the internet. This extensive training enables CLIP to effectively classify images based on any label provided by the user."[^2]
When you type a prompt, systems using CLIP create embeddings that bridge text and image representations. This embedding then guides each denoising step, steering the transformation from noise toward an image matching your description.

Part II: The Memorization Question—When Learning Becomes Copying
The Memorization Discovery
In a landmark 2023 study, Carlini et al. from Google and DeepMind made a striking discovery: "Image diffusion models such as DALL-E 2, Imagen, and Stable Diffusion... memorize individual images from their training data and emit them at generation time."[^1]
Their findings were specific and measurable. Using what they call a "generate-and-filter pipeline," they report extracting "over a thousand training examples from state-of-the-art models, ranging from photographs of individual people to trademarked company logos."[^1] This extraction required targeted prompting and filtering across many generations—it's not the typical output behavior, but it demonstrates that memorization is possible and does occur.
One particularly vivid example they documented: when prompted with "Ann Graham Lotz," Stable Diffusion generated an image nearly identical to a training photo, with an L2 distance of only 0.031—essentially a near-perfect reproduction.[^1] This represents a clear case of memorization rather than novel generation.
The researchers found that duplicated training examples are "orders of magnitude more likely to be memorized than non-duplicated examples,"[^1] and concluded that "diffusion models are much less private than prior generative models such as GANs."[^1]
Important context: This demonstrates that memorization can occur, particularly under specific conditions. It does not mean every generation—or even most generations—involves direct copying.
When the Model Doesn't Copy
The same research reveals important nuances. When prompted to generate "A Photograph of Barack Obama," Stable Diffusion produced an entirely recognizable image of Obama—but it wasn't a copy of any specific training image. The four nearest training images all had distances above 0.3, indicating substantial differences.[^1]
As the researchers note, this raises a fundamental question: "whether their impressive results arise from truly novel generations, or are instead the result of direct copying and remixing of their training data."[^1]
Their measured conclusion: both occur. The models genuinely generate novel combinations in most cases, but they also can memorize and reproduce near-exact training examples when prompted appropriately.
The Frequency Dependence
Critically, memorization correlates strongly with training data frequency. Images that appear once are rarely memorized. Images that appear many times in training data become increasingly likely to be memorized.[^1] While frequency appears to be a major factor, other variables likely contribute as well.
This suggests the memorization isn't solely a fundamental limitation of the architecture—it's also influenced by dataset composition and curation practices.
The Uniqueness of Most Generations
Every generation involves probabilistic uniqueness due to random noise initialization. As Kabir et al. observe, "The probability of producing the same AI-generated image in Stable Diffusion by a different individual is significantly minimal."[^2]
Put more clearly: generating identical outputs by chance is extraordinarily unlikely. Each generation starts from different random noise and includes stochastic elements (random variations) at each denoising step. The variables involved—prompt wording, random seed, model version, sampling steps, guidance scale—combine to make exact duplication through independent generation essentially impossible.
The key distinction: While each pixel arrangement is likely unique, the patterns, compositions, and styles all derive from training data. The question isn't whether the specific pixels existed before—they almost certainly didn't. The question is whether the underlying patterns constitute derivative use of copyrighted material.
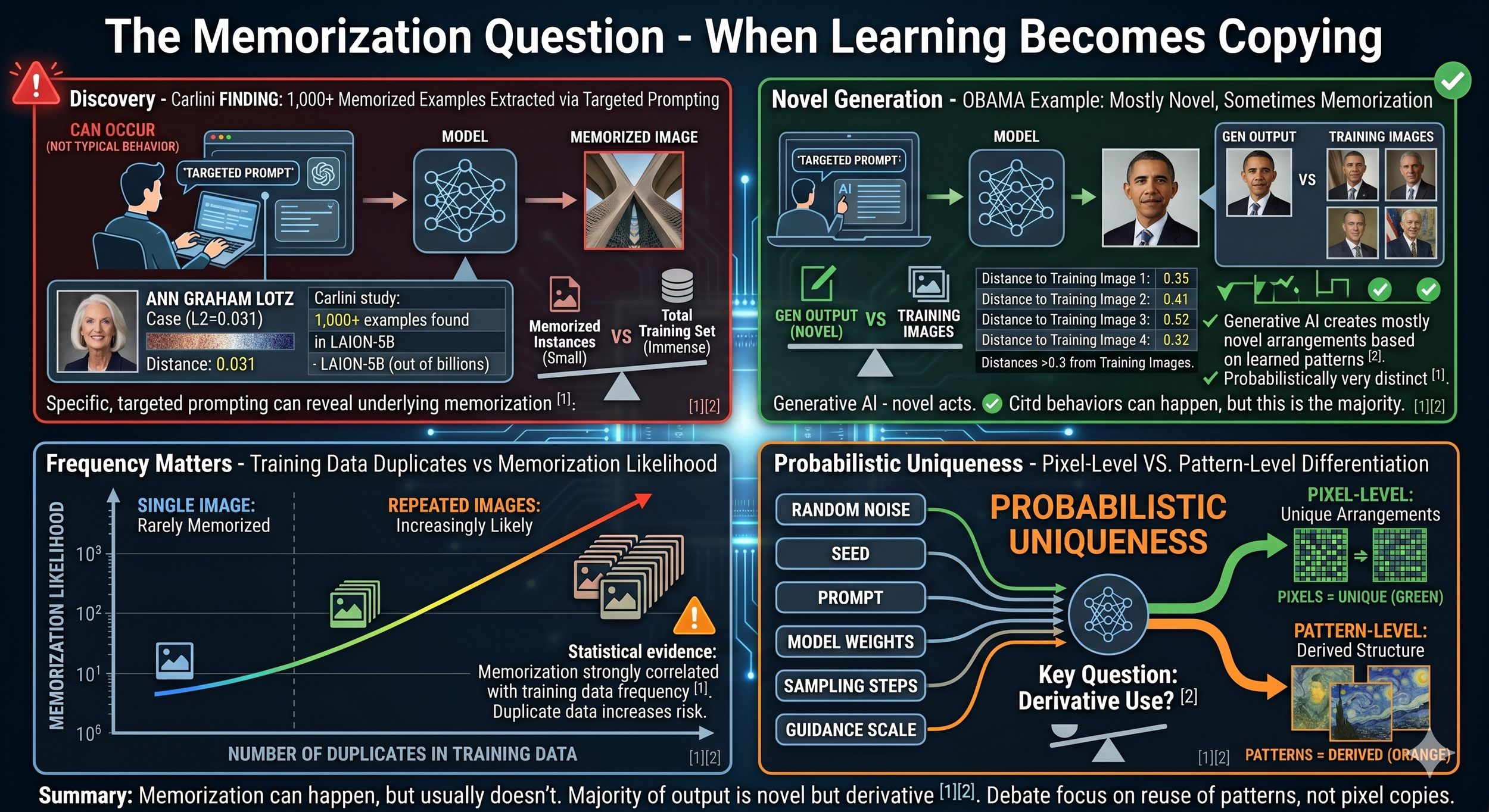
Figure: The Memorization Question - When Learning Becomes Copying
Top Left: Carlini et al. (2023) demonstrated that diffusion models can memorize training examples, extracting over 1,000 near-exact copies through targeted prompting and filtering—though this represents a tiny fraction of billions of training images. The Ann Graham Lotz case showed near-perfect reproduction (L2 distance 0.031). Importantly, this is an edge case, not typical output behavior.[^1][^2]
Top Right: The same research shows most generations are novel. When prompted for "Barack Obama," the model produced recognizable outputs with L2 distances >0.3 from all training images—statistically distinct, demonstrating genuine generation rather than memorization. Both behaviors occur: memorization under specific conditions, novel generation in typical cases.[^1][^2]
Bottom Left: Memorization correlates strongly with training data frequency. Images appearing once are rarely memorized (low on logarithmic scale), while images appearing hundreds or thousands of times become increasingly likely to be reproduced (exponential increase). Dataset curation and deduplication can mitigate this risk.[^1][^2]
Bottom Right: Every generation is probabilistically unique due to six variables (random noise initialization, seed, prompt, model weights, sampling steps, guidance scale). At the pixel level, outputs are statistically unique arrangements. At the pattern level, all learned structure derives from training data. The unresolved legal question: whether pattern-level derivation constitutes copyright infringement, even when pixel arrangements are novel.[^1][^2]
Part III: The Data Problem—Scale, Bias, and Copyright
Training Data Requirements
The scale of training data is staggering. According to Gokaslan et al.'s 2024 research, models like Stable Diffusion 2 were trained on the LAION dataset, which contains billions of image-text pairs scraped from the internet.[^3]
However, their research revealed something surprising: "We achieve comparable performance to public Stable Diffusion 2... using entirely Creative-Commons-licensed (CC) images," requiring "as little as 3% of the LAION data (i.e., roughly 70 million examples)."[^3]
This finding suggests—though doesn't definitively prove—that data quality and curation may matter more than raw quantity, though 70 million images is still an enormous corpus.
The Bias Amplification Problem
Miao et al.'s 2024 study documented a concerning pattern: "Diffusion models inherit and amplify data bias from the large-scale, uncurated training data, showing undesired behaviors under specific conditions."[^4]
Their documented example is telling: "Given the text prompt, 'a photo of a programmer', StableDiffusion generates almost all males, whereas female programmers are dramatically underrepresented."[^4] This represents one experimental result demonstrating how training data biases manifest in outputs.
This isn't a minor glitch—it reflects what the researchers call "conditional mode collapse" (essentially, reduced output diversity under certain settings), where "generated images show high uniformity under high guidance scales."[^4] The models don't just learn what things look like; they learn and can reinforce statistical biases present in their training data.
Synthetic Captioning: One Copyright-Conscious Approach
One innovative approach to copyright concerns involves synthetic caption generation. Gokaslan et al. describe their method: "We use an intuitive transfer learning technique to produce a set of high-quality synthetic captions paired with our assembled CC images."[^3]
They call this approach "telephoning"—using one AI model (BLIP-2) to generate captions for images, then using those synthetic captions to train a different AI model (a diffusion model). This allows training on images that lack native text descriptions.
Importantly, their CommonCanvas model, trained exclusively on Creative Commons-licensed images with synthetic captions, "achieves comparable performance to SD2 on human evaluation... even though we use a synthetically captioned CC-image dataset that is only <3% the size of LAION."[^3]
This study demonstrates that competitive diffusion models can be trained on licensed data, though it doesn't resolve legal questions about models already trained on copyrighted material.
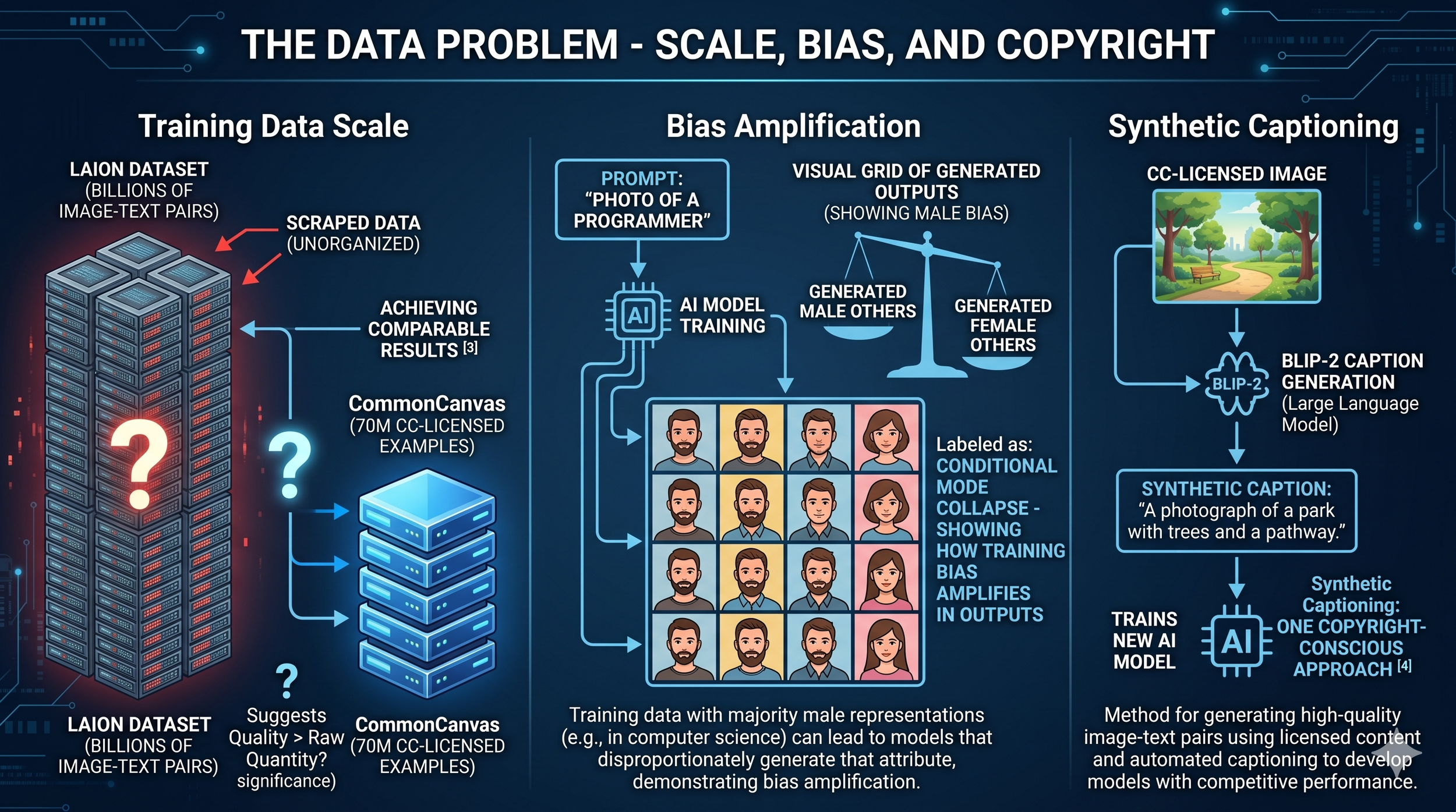
Figure: The Data Problem - Scale, Bias, and Copyright
Left: Research comparing training data scale versus quality. While Stable Diffusion 2 was trained on billions of scraped LAION image-text pairs, Gokaslan et al. (2024) achieved comparable performance using only 70 million Creative Commons-licensed images, suggesting data curation may be more important than raw scale—though 70 million remains an enormous dataset.[^3]
Center: Bias amplification documented by Miao et al. (2024). When prompted with "a photo of a programmer," Stable Diffusion generated predominantly male outputs, demonstrating how training data biases (e.g., underrepresentation of women in computer science imagery) become amplified in model outputs through conditional mode collapse.[^4]
Right: Synthetic captioning ("telephoning") as one copyright-conscious approach. Large language models like BLIP-2 generate captions for unlabeled Creative Commons images, enabling training of competitive diffusion models without relying on copyrighted image-text pairs. This demonstrates licensed training is technically viable but doesn't resolve questions about existing models trained on copyrighted data.[^3][^4]
Part IV: The Legal Battle—Getty Images v. Stability AI
The Lawsuit
The theoretical concerns about copyright became concrete when Getty Images sued Stability AI. As Dubinski et al. note in their 2025 research, "Getty Images, a leading visual media company, filed a lawsuit against Stability AI, the creators of Stable Diffusion, alleging the unauthorized use of copyright-protected images."[^5]
The case drew particular attention because, as the researchers explain, "it has been shown that DMs are capable of generating verbatim copies of their training data at inference time."[^5] Though not routine behavior, this capability raised questions about whether the models function as unauthorized reproduction mechanisms.
The UK Ruling (November 2025): What It Actually Decided
The first major decision came from the UK High Court in November 2025. The outcome was mixed, and critically, it resolved only narrow procedural and evidentiary issues—not the broader legal questions about AI training.
Copyright Claims: Dismissed, But Not on the Merits
The court dismissed Getty's secondary copyright infringement claims. However, this dismissal came after Getty had "abandoned most of its claims" before trial, including what legal observers called "the major crux of this case," because Getty "was unable to provide evidence that Stability AI had undertaken any acts of unauthorised copying in the UK."[^6]
This wasn't a ruling that "training on copyrighted data is legal" or that "AI generation doesn't infringe copyright." It was a procedural dismissal based on Getty's inability to prove specific acts of copying occurred within UK jurisdiction with the evidence they presented.
Trademark Claims: Narrow Victory for Getty
The court found "extremely limited" trademark infringement where Stable Diffusion generated images displaying Getty's watermark.[^6] Importantly, the court "rejected Stability AI's attempt to hold the user responsible for that infringement, confirming that responsibility for the presence of such trademarks lies with the model provider, who has control over the images used to train the model."[^7]
This establishes at least one point of liability: model providers can be responsible for trademark-bearing outputs.
What the Ruling Leaves Unresolved
The case touched on the question of whether "intangible articles, such as AI models, are subject to copyright infringement claims,"[^7] but it did not definitively resolve:
Whether training on copyrighted material constitutes copyright infringement in general
Whether generated outputs are derivative works of training data
How copyright law applies when the connection between training data and output is probabilistic rather than deterministic
Fair use questions (a US legal doctrine with no direct UK equivalent)
Getty's own statement after the ruling is revealing: "We invested millions of pounds to reach this point with only one provider that we need to continue to pursue in another venue."[^7]
They urged governments to "establish stronger transparency rules which are essential to prevent costly legal battles and to allow creators to protect their rights,"[^7] implicitly acknowledging that existing legal frameworks are insufficient for resolving these questions cleanly.
The US case was still pending as of the ruling, and different jurisdictions may reach different conclusions on similar facts.

Figure: Getty Images v. Stability AI - What the UK Ruling Actually Decided
The Lawsuit (Left): Getty Images sued Stability AI alleging unauthorized use of copyrighted images in training Stable Diffusion and the model's capability to generate verbatim copies.[^5]
UK High Court Ruling - November 2025 (Center): The court delivered a mixed outcome that resolved only narrow procedural issues. Copyright claims were dismissed after Getty abandoned most claims pre-trial, unable to prove specific unauthorized copying within UK jurisdiction. Critically, this was not a ruling that training on copyrighted data is legal—it was a procedural dismissal based on evidentiary gaps.[^6] The court found "extremely limited" trademark infringement where generated images displayed Getty's watermark, establishing that model providers, not users, bear responsibility for such outputs.[^6][^7]
Unresolved Questions (Right): The ruling left fundamental questions unanswered: whether training on copyrighted material constitutes infringement, whether generated outputs are derivative works, how copyright applies when training-to-output connections are probabilistic rather than deterministic, and fair use considerations (a US doctrine with no UK equivalent). The US case remains pending, and different jurisdictions may reach different conclusions.[^6][^7]
Getty's Post-Ruling Statement (Bottom): Getty acknowledged investing "millions of pounds" while urging governments to establish stronger transparency rules, implicitly recognizing that existing legal frameworks are insufficient for resolving AI copyright questions.[^7]
Part V: Detection and Forensics
Spectral Signatures of AI Generation
AI-generated images aren't always perfect forgeries. Bammey's 2023 research found that "diffusion models leave inherent frequency artefacts" during generation that can be detected through spectral analysis.[^8]
These artifacts appear in the Fourier transform of images and can be revealed using high-pass filters. According to the research, they're "distinguishable even under mild JPEG compression"[^8] and differ from compression artifacts, potentially making them useful for forensic identification.
However, as Bammey notes, "these artefacts are subtle and not immediately visible, they must be revealed with suitable filters."[^8]
Copyrighted Data Identification (CDI)
For data owners trying to prove their images were used in training, Dubinski et al. developed a framework called Copyrighted Data Identification (CDI).[^5]
The innovation is moving from individual image detection to dataset-level inference: "Instead of using the membership signal from a single data point, CDI leverages the fact that most data owners, such as providers of stock photography, visual media companies, or even individual artists, own datasets with multiple publicly exposed data points which might all be included in the training."[^5]
Their research claims that their system allows "data owners with as little as 70 data points to identify with a confidence of more than 99% whether their data was used to train a given DM."[^5] If validated by independent verification, this provides a practical tool for copyright enforcement that individual membership inference attacks couldn't achieve.

Figure: Detection and Forensics - Two Approaches to Identifying AI-Generated Images
Left - Spectral Signatures (Bammey 2023): AI-generated images may appear visually indistinguishable from natural photographs, but Fourier transform analysis reveals subtle frequency artifacts left by diffusion models. These artifacts appear as grid-like patterns in the frequency domain (circled in red) that differ from natural image characteristics. High-pass filtering can reveal these artifacts even after mild JPEG compression. However, the artifacts are subtle and require specialized analysis techniques and expertise—they are not visible through casual inspection, limiting their use for general authentication while providing value for forensic analysis.[^8]
Right - Copyrighted Data Identification (CDI) (Dubinski et al. 2025): Individual image membership detection provides insufficient signal for proving training set usage. CDI innovates by leveraging dataset-level inference: aggregating signals from multiple images owned by the same entity (stock photographers, media companies, artists) to achieve statistical confidence. The research claims that as few as 70 data points from a single owner can identify training set inclusion with >99% confidence. This approach addresses the practical reality that most copyright holders own portfolios rather than single images. The technique's effectiveness awaits independent validation, but if verified, could provide practical copyright enforcement capabilities.[^5]
Critical Note: Both methods have inherent limitations and neither represents perfect detection. Spectral analysis requires expertise and may be circumvented by model improvements. CDI's claimed effectiveness requires independent validation and may face challenges from adversarial training techniques.
Part VI: Educational and Practical Implications
Comparative Capabilities (As of 2023)
Derevyanko and Zalevska's 2023 comparative analysis examined three major platforms for educational use.[^9] Note that the AI product landscape evolves rapidly, so these characterizations may become dated:
Stable Diffusion:
Open-source architecture (though specific licenses and model weights vary by version)
"High stability and visual accuracy"
Requires significant GPU resources for local deployment
Offers full control over generation process when self-hosted
Midjourney:
Proprietary cloud-based service
"Ability to create images that match text descriptions, adding style and design elements"
Subscription-based access
Known for artistic, stylized outputs
DALL-E 2:
OpenAI's proprietary system (now succeeded by DALL-E 3)
"Creativity in generating new images by combining different elements and concepts"
API-based access
Implemented safety filters and content policies
Each has "unique characteristics and approaches to image creation,"[^9] with different strengths for various use cases.
The 3D Extension
Recent research is extending these principles beyond 2D images. Karnewar et al.'s 2023 HOLODIFFUSION research presented "the first 3D-aware generative diffusion model that produces 3D-consistent images and is trained with only posed 2D image supervision."[^10]
This addresses both the scarcity of 3D training data and the computational challenges of working in three dimensions, demonstrating that diffusion principles can extend beyond flat images.
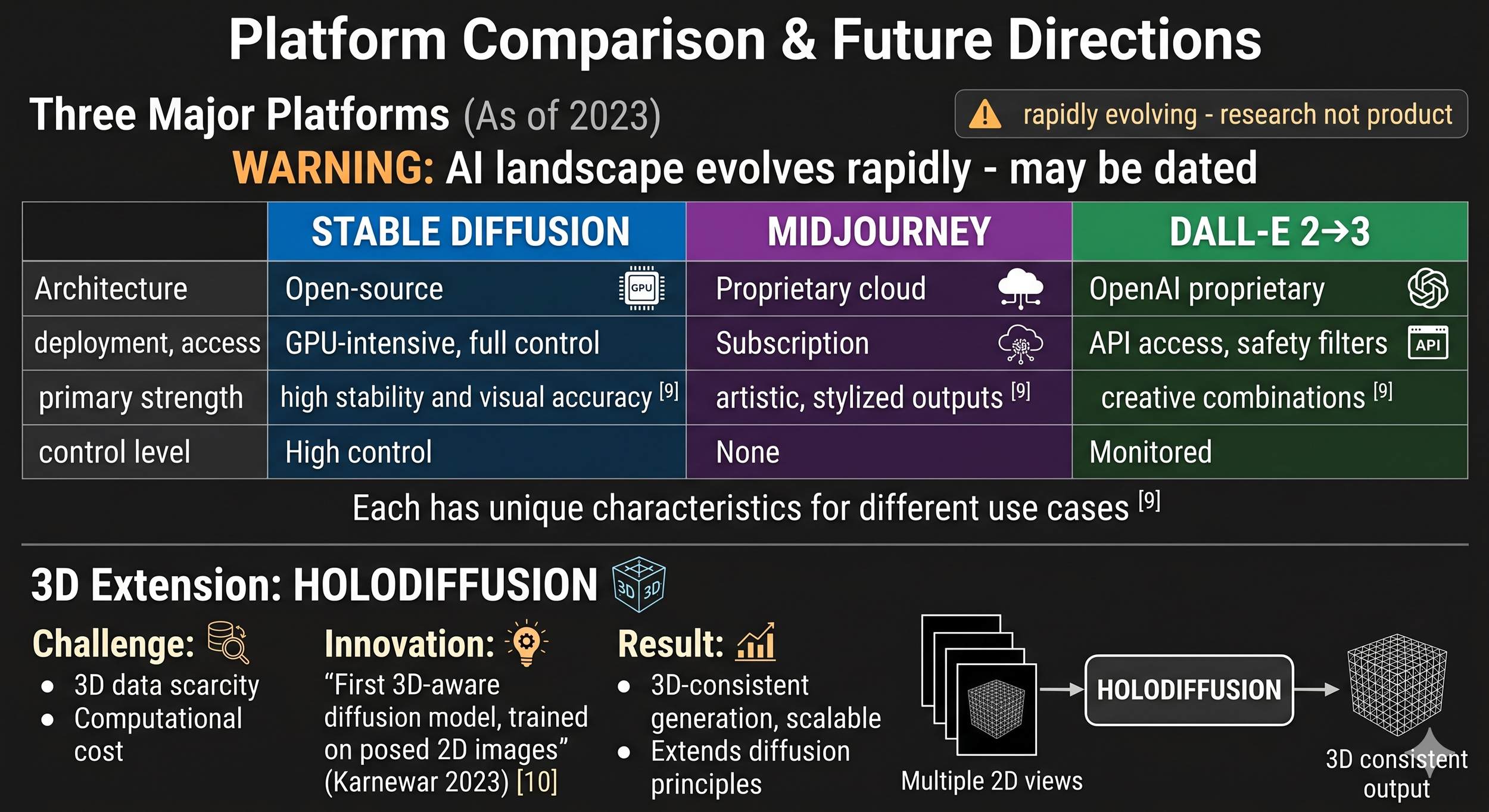
Figure: Educational and Practical Implications - Platform Comparison and Future Directions
Top - Three Major Platforms (As of 2023): Comparison of AI image generation platforms based on Derevyanko and Zalevska's 2023 educational analysis. Stable Diffusion offers open-source architecture with high technical control but requires significant GPU resources for local deployment. Midjourney provides proprietary cloud-based access via subscription model, known for artistic and stylized outputs. DALL-E 2 (succeeded by DALL-E 3) offers API-based access with implemented safety filters and content moderation. Each platform has distinct characteristics suited to different use cases—technical experimentation versus artistic creation versus regulated commercial use. The AI product landscape evolves rapidly; these 2023 characterizations may be outdated.[^9]
Bottom - 3D Extension: HOLODIFFUSION: Karnewar et al.'s 2023 research extends diffusion principles to three-dimensional generation. Traditional 3D generative models face challenges from training data scarcity and cubic computational scaling. HOLODIFFUSION addresses both by training on posed 2D image sequences (multiple viewpoints of 3D scenes) rather than requiring expensive 3D volumetric data, while producing 3D-consistent outputs. This demonstrates diffusion model principles can extend beyond flat images to volumetric/spatial generation, with potential applications in 3D modeling, AR/VR, and spatial computing. This represents a research direction, not a deployed consumer product.[^10]
Conclusion: What We Know and What Remains Uncertain
The Technical Reality
AI image generation through diffusion models typically operates through:
Iterative denoising of random noise guided by learned statistical patterns
Latent space compression (in many modern implementations) for computational efficiency
Text-image embedding for natural language control
Probabilistic sampling creating unique pixel arrangements each time
Pattern learning from massive datasets (millions to billions of images)
Crucially: In typical operation, this is not retrieval-and-assembly of stored image fragments. The system applies learned transformations to random noise. The process is generative in a technical sense—it creates new pixel arrangements that didn't exist before. Memorization, while real and documented, appears to be the exception rather than the rule.
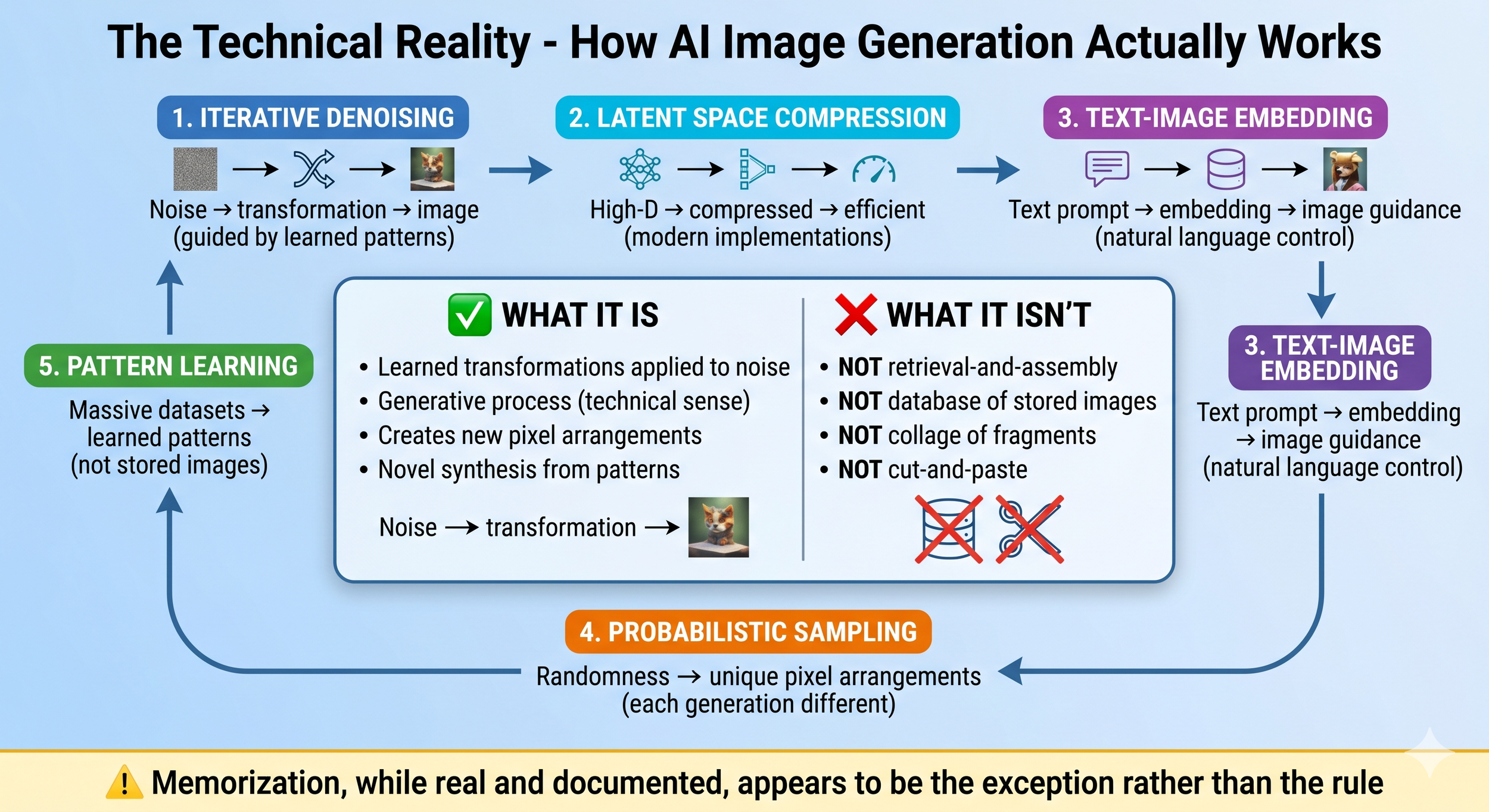
Figure: The Technical Reality - How AI Image Generation Actually Works
AI image generation through diffusion models operates as an integrated system of five key processes: (1) Iterative denoising progressively transforms random noise into coherent images guided by learned patterns; (2) Latent space compression (in modern implementations) enables computational efficiency by working in lower-dimensional representations; (3) Text-image embedding translates natural language prompts into mathematical guidance for the generation process; (4) Probabilistic sampling ensures each generation produces unique pixel arrangements; (5) Pattern learning from massive datasets (millions to billions of images) provides the statistical knowledge that guides generation—critically, these are learned patterns, not stored images.
Central Synthesis: This process is generative—applying learned transformations to random noise to create new pixel arrangements. It is not retrieval-and-assembly from a database of stored image fragments, not a collage operation, and not cut-and-paste copying. However, all learned patterns derive entirely from training data, creating a nuanced middle ground: the pixels are genuinely novel, but the patterns, styles, and compositional knowledge come from existing images.
Important Caveat: While memorization of specific training examples can occur (particularly for frequently duplicated images), research suggests this is the exception rather than typical behavior. Most generations represent novel synthesis from learned patterns rather than reproduction of training examples.
The Memorization Reality
Research has revealed that these models:
Can memorize training examples, particularly when those examples appear frequently in training data
Do reproduce near-exact copies under specific prompting conditions (documented through targeted research)
Usually generate novel pixel arrangements rather than direct copying in typical use
Always operate within constraints learned from training data—they cannot generate patterns they haven't learned
The frequency of memorization during normal use remains an active research question. While Carlini et al. extracted over 1,000 near-exact copies, this required targeted prompting and filtering. The baseline rate during casual use appears lower, though precise statistics across different use cases remain uncertain.
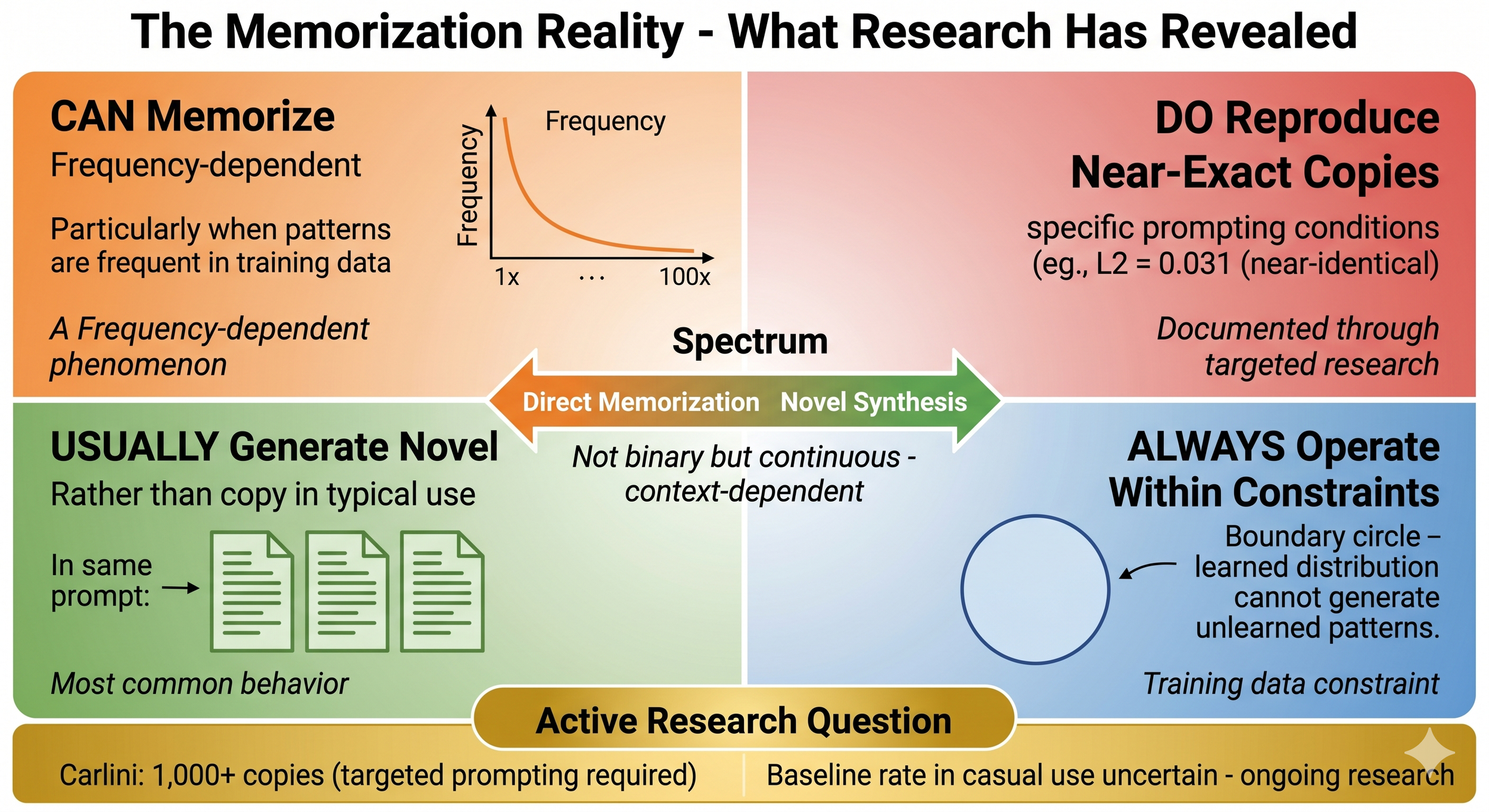
Figure: The Memorization Reality - Four Key Research Findings
Research reveals a nuanced picture of how diffusion models handle training data, best understood as a spectrum rather than a binary:
CAN Memorize (Top Left): Models can memorize training examples through a frequency-dependent phenomenon. Images appearing once in training data are rarely memorized, while images appearing 100+ times become increasingly likely to be reproduced. Memorization correlates strongly with training data duplication.
DO Reproduce Near-Exact Copies (Top Right): Near-exact reproductions have been documented under specific prompting conditions. Carlini et al. extracted examples with L2 distances as low as 0.031 (near-identical). This demonstrates memorization is real and measurable, though it required targeted prompting and filtering to find these cases.
USUALLY Generate Novel (Bottom Left): In typical use, models generate novel pixel arrangements rather than copying. When given the same prompt multiple times, outputs vary while remaining conceptually similar. This appears to be the most common behavior in casual, everyday use.
ALWAYS Operate Within Constraints (Bottom Right): Models operate entirely within the distribution of learned patterns from training data. They cannot reliably generate patterns outside the boundary of what they learned during training—a fundamental constraint, not a temporary limitation.
Active Research Question (Bottom): While Carlini et al. demonstrated memorization exists by extracting 1,000+ near-exact copies, this required targeted prompting across billions of potential generations. The baseline rate of memorization during casual use appears lower but remains uncertain. Precise statistics across different use cases, prompts, and models are an active area of ongoing research.
The Honest Answer to "Is It a Collage?"
No, in the literal sense. Diffusion models don't typically assemble visible pieces from existing images. They don't store a database of images or image fragments to retrieve during normal operation.
However, they learn every pattern, style, composition rule, and visual concept from existing images. They cannot reliably generate patterns that fall completely outside the distribution they learned from training data—though exactly how strictly this constraint operates remains a subject of ongoing research and debate.
The better analogy might be: a musician who learned by listening to thousands of songs. When they improvise, they're not playing back recordings or splicing together clips. They're applying learned patterns in novel combinations. But everything they know about music came from what they heard.
Is that derivative? Transformative? Fair use? The law hasn't definitively answered these questions for human musicians across all contexts, and it certainly hasn't answered them for AI systems.
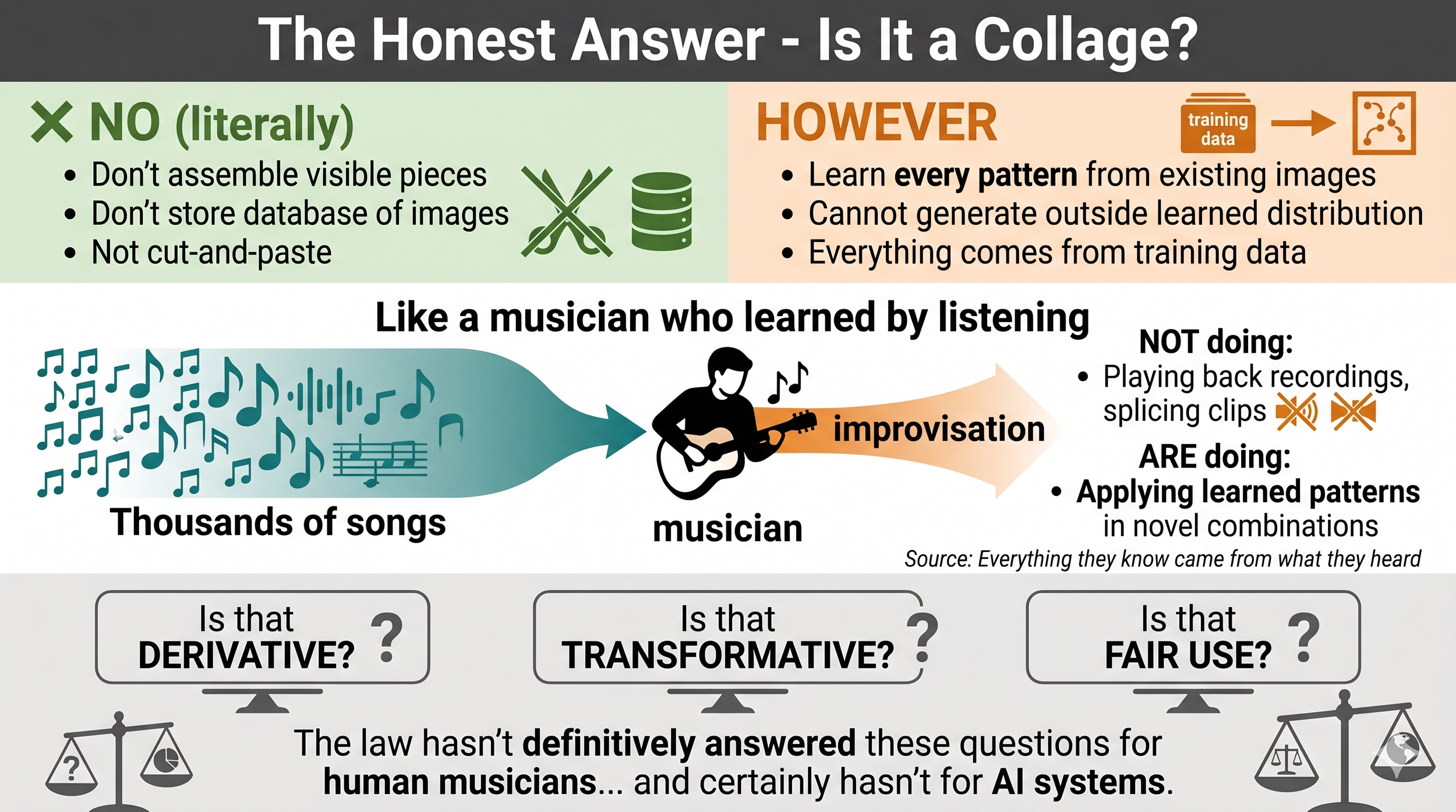
Figure: The Honest Answer - Is AI Image Generation a Collage?
No, in the literal sense (left, green). Diffusion models don't assemble visible pieces from existing images, don't store a database of images to retrieve from, and don't operate through cut-and-paste mechanisms.
However, with critical context (right, orange). These models learn every pattern, style, and composition rule from existing images. They cannot generate patterns outside the learned distribution. Everything comes from training data—the patterns are learned, not the images stored.
The Musician Analogy (center). Like a musician who learned by listening to thousands of songs: when improvising, they're not playing back recordings or splicing clips—they're applying learned patterns in novel combinations. Yet everything they know came from what they heard. AI works similarly: pattern application, not content retrieval.
Unresolved Legal Questions (bottom, gray). Is this derivative? Transformative? Fair use? These questions remain genuinely open. The law hasn't definitively answered them for human musicians across contexts, and certainly hasn't for AI systems. Legal uncertainty persists across jurisdictions.
What the "Lossy Compression" Metaphor Gets Right and Wrong
The phrase "lossy compression of the training set" captures something true: the model's knowledge is entirely derived from training data, compressed into parameters that can generate similar outputs.
What it risks obscuring: the model doesn't decompress back to training images in normal operation. It synthesizes new arrangements from learned statistical patterns. The "compression" isn't like a zip file that unpacks to originals—it's more like learning general rules from specific examples.
When memorization occurs (which is real but appears to be the exception rather than the rule), it's often because those examples appeared frequently enough that the "general rule" the model learned effectively became "reproduce this specific thing." But frequency isn't the only factor—model architecture, training procedures, and prompt specificity likely all play roles.
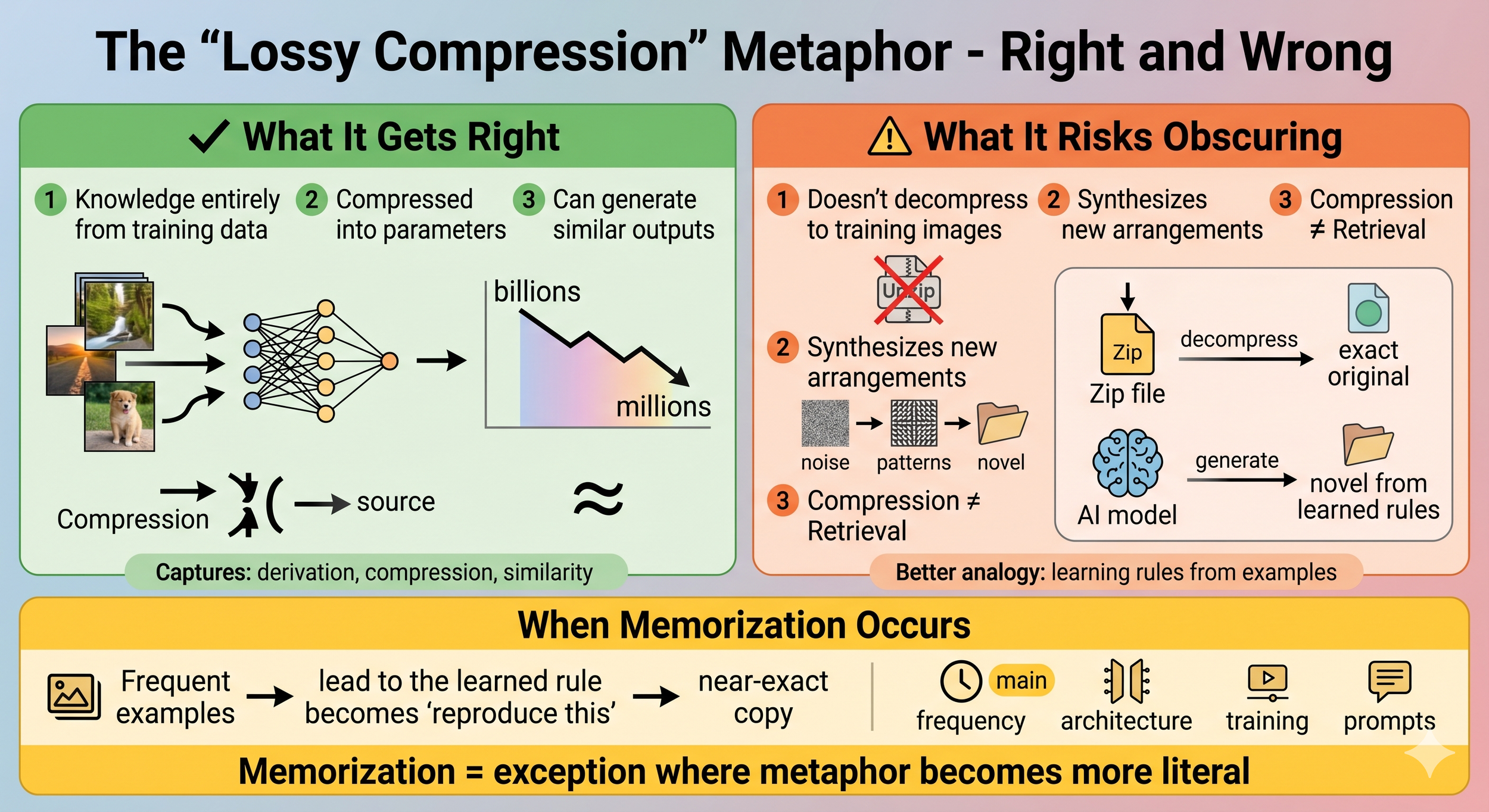
A three-panel infographic. The left green panel lists what the lossy compression metaphor gets right: AI knowledge derives from training data, is compressed into parameters, and can produce similar outputs. The right orange panel identifies limitations: unlike a zip file, an AI model doesn't decompress to retrieve training data — it synthesizes new arrangements from learned rules. A bottom gold panel notes that memorization is the exception, occurring when frequent examples cause the learned rule to become near-exact reproduction.
Outstanding Questions
Several critical questions remain unresolved:
Technical:
What percentage of generations involve meaningful memorization versus novel synthesis across different use cases?
Can we build models that generate effectively without memorizing specific examples?
How do we measure the line between learning patterns and copying content?
Legal:
Does training on copyrighted material constitute copyright infringement?
Are generated images derivative works of training data?
How does fair use apply when the relationship to training data is statistical rather than mechanical?
Do different legal jurisdictions reach different conclusions on these questions?
Ethical:
How should creators whose work enabled these systems be compensated?
Can we mitigate bias without sacrificing capability?
What transparency should be required for training datasets?
Where do we draw the line between inspiration and appropriation?
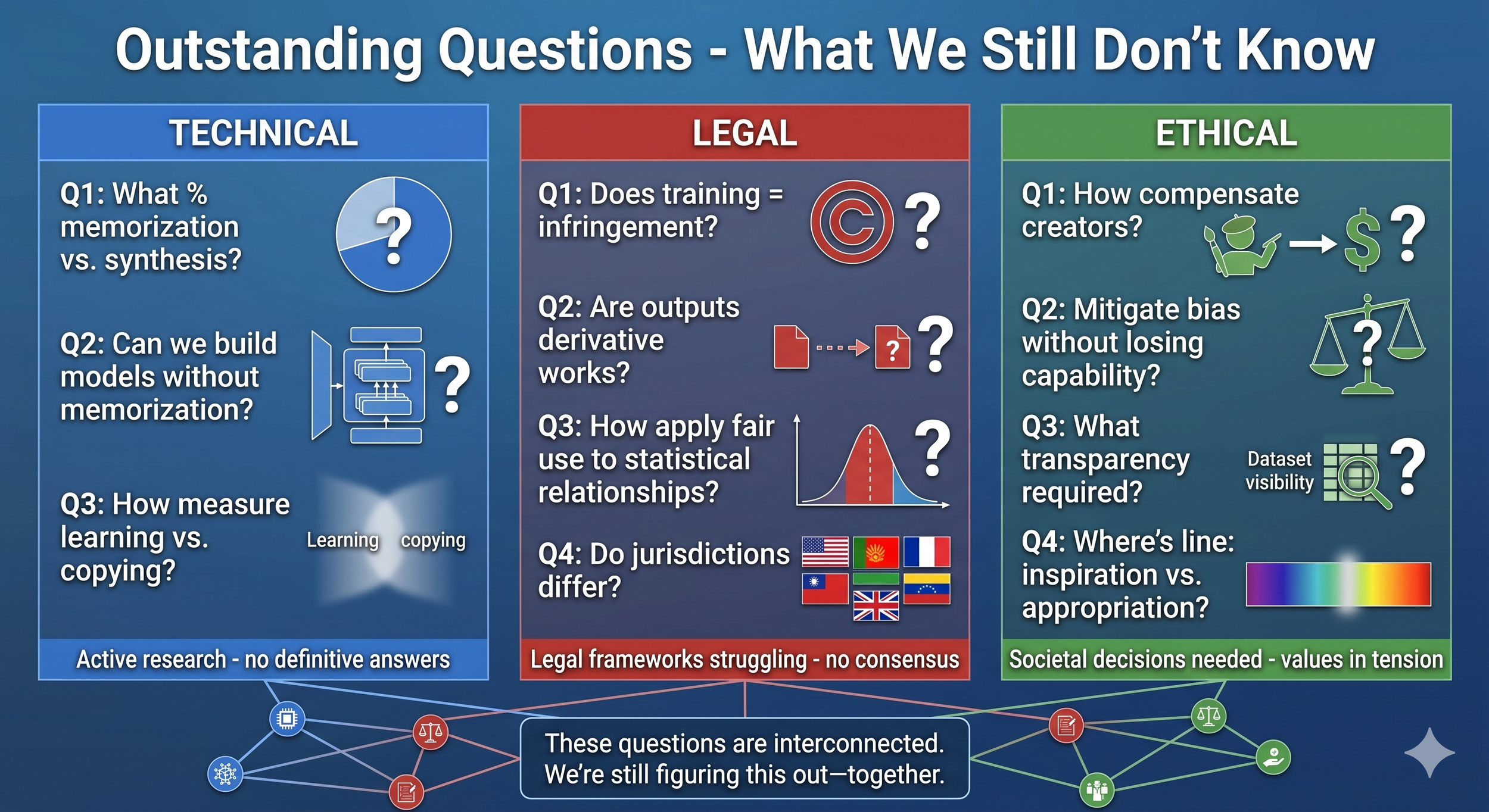
Figure: Outstanding Questions - What We Still Don't Know
Critical questions remain unresolved across three interconnected domains:
Technical Questions (Left, Blue): What percentage of generations involve meaningful memorization versus novel synthesis across different use cases? Can we build models that generate effectively without memorizing specific training examples? How do we measure the boundary between learning statistical patterns and copying content—where exactly does that blurry line fall? These are active research areas with no definitive answers yet.
Legal Questions (Center, Red): Does training on copyrighted material constitute copyright infringement? Are generated images derivative works when the relationship to training data is statistical rather than direct? How does fair use doctrine apply to probabilistic pattern learning versus mechanical copying? Do different legal jurisdictions reach different conclusions on these questions? Legal frameworks are struggling to adapt, with no consensus emerging. The Getty Images UK ruling resolved narrow procedural issues but left fundamental questions open.
Ethical Questions (Right, Green): How should creators whose work enabled these systems be compensated? Can we mitigate bias in model outputs without sacrificing generation capability—or is there an inherent tradeoff? What level of transparency should be required for training datasets? Where do we draw the line between inspiration and appropriation—a question spanning cultural, legal, and philosophical domains? These require societal decisions navigating values in tension.
Interconnections (Bottom): These questions don't exist in isolation. Technical research provides evidence for legal decisions. Legal frameworks reflect ethical values. Ethical considerations guide technical development priorities. No single discipline can resolve these questions alone—they require collaboration among researchers, policymakers, and society. We are genuinely still figuring this out together.
The Bigger Picture
The Getty Images case demonstrates that existing legal frameworks struggle with AI generation. The technical reality—that models typically learn statistical patterns rather than storing retrievable images, yet can still reproduce training examples under certain conditions—doesn't map cleanly onto copyright doctrines developed for human creators and traditional copying.
As Carlini et al. frame it: "Our results show that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training."[^1]
We're not just dealing with a new technology—we're dealing with a new category of creation that operates through statistical learning rather than either pure originality or mechanical copying. The truth resists the simple narratives offered by both AI enthusiasts ("it's just a tool learning patterns like humans do") and critics ("it's just theft with extra steps").
The most honest summary: Diffusion models typically generate through learned pattern application to random noise—genuinely creating novel pixel arrangements in most documented cases. However, they learned those patterns exclusively from existing images, can memorize specific training examples (particularly frequently-appearing ones), and operate entirely within the distribution of their training data. Whether this constitutes transformative fair use or derivative infringement remains legally unresolved and may vary by jurisdiction, use case, and how courts ultimately interpret the statistical nature of the relationship to training data.
The research makes one thing clear: facile answers don't survive contact with the technical and legal complexity. Both "it's completely original" and "it's just collage" are oversimplifications. The reality is messier, more interesting, and more challenging than either narrative allows.
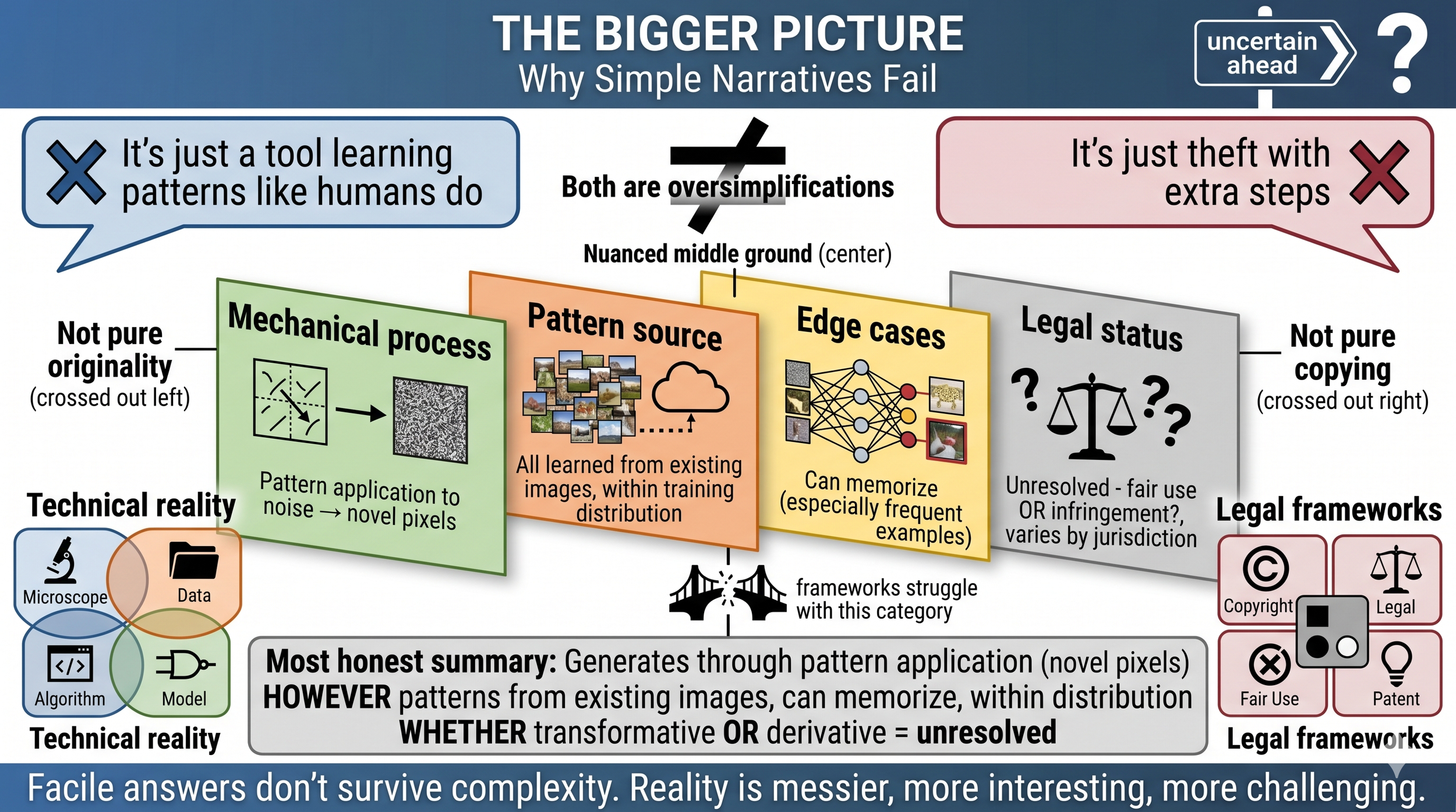
Figure: The Bigger Picture - Why Simple Narratives Fail
Competing Oversimplifications (Top): Public discourse is dominated by two incompatible simple narratives. Enthusiasts frame AI generation as "just a tool learning patterns like humans do"—pure originality and transformative creation. Critics frame it as "just theft with extra steps"—pure copying and derivative infringement. Both oversimplify a genuinely complex reality that resists these categorizations.
The Complex Reality (Center, Four Layers): Four simultaneously true aspects create irreducible complexity: (1) Mechanical process (green): Models apply learned patterns to random noise, genuinely creating novel pixel arrangements in most cases—this is generative, not retrieval; (2) Pattern source (orange): All patterns learned exclusively from existing images; models operate within training data distribution—all knowledge derives from prior work; (3) Edge cases (yellow): Models can memorize and reproduce specific examples, especially frequently-appearing ones—memorization is real though exceptional; (4) Legal status (gray): Whether this constitutes transformative fair use or derivative infringement remains unresolved and may vary by jurisdiction and interpretation. The reality is neither pure originality (left annotation crossed out) nor pure copying (right annotation crossed out)—it occupies a nuanced middle ground.
The Technical-Legal Mismatch (Bottom): Technical reality (left) operates through overlapping, interconnected processes—research, data, algorithms, and models form a fluid system. Legal frameworks (right) were developed as discrete categories—copyright, fair use, patents—with clear boundaries. The broken bridge icon represents the structural incompatibility: existing legal frameworks struggle to map onto this new category of creation operating through statistical learning.
The Most Honest Summary (Gray Box): Diffusion models generate through learned pattern application, creating novel pixel arrangements. However, they learned patterns exclusively from existing images, can memorize specific examples, and operate within training data distribution. Whether this constitutes transformative fair use or derivative infringement remains genuinely unresolved—a legal question that may receive different answers across jurisdictions.
Conclusion (Bottom Banner): As the research demonstrates, facile answers don't survive contact with the technical and legal complexity. The reality is messier, more interesting, and more challenging than either simple narrative allows. We need new frameworks for this new category of creation.
References
[^1]: Carlini, N., Hayes, J., Nasr, M., Jagielski, M., Sehwag, V., Tramèr, F., Balle, B., Ippolito, D., & Wallace, E. (2023). Extracting Training Data from Diffusion Models. 32nd USENIX Security Symposium, 5253-5270.
[^2]: Kabir, A. I., Mahomud, L., Fahad, A. A., & Ahmed, R. (2024). Empowering Local Image Generation: Harnessing Stable Diffusion for Machine Learning and AI. Informatica Economică, 28(1), 25-35.
[^3]: Gokaslan, A., Cooper, A. F., Collins, J., Seguin, L., Jacobson, A., Patel, M., Frankle, J., Stephenson, C., & Kuleshov, V. (2024). CommonCanvas: Open Diffusion Models Trained on Creative-Commons Images. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 8250-8260.
[^4]: Miao, Z., Wang, J., Wang, Z., Yang, Z., Wang, L., Qiu, Q., & Liu, Z. (2024). Training Diffusion Models Towards Diverse Image Generation with Reinforcement Learning. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10844-10854.
[^5]: Dubinski, J., Kowalczuk, A., Boenisch, F., & Dziedzic, A. (2025). CDI: Copyrighted Data Identification in Diffusion Models. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 18674-18683.
[^6]: Multiple legal analyses of Getty Images (US) Inc & Ors v. Stability AI Limited [2025] EWHC 2863 (Ch), decided November 4, 2025, from Bird & Bird, Pinsent Masons, and Ropes & Gray.
[^7]: Getty Images Holdings, Inc. Form 8-K filing (2025) regarding UK High Court decision in Getty Images v. Stability AI.
[^8]: Bammey, Q. (2023). Synthbuster: Towards Detection of Diffusion Model Generated Images. IEEE Open Journal of Signal Processing, 5, 1-13.
[^9]: Derevyanko, N., & Zalevska, O. (2023). Comparative analysis of neural networks Midjourney, Stable Diffusion, and DALL-E and ways of their implementation in the educational process of students of design specialities. Scientific Bulletin of Mukachevo State University. Series "Pedagogy and Psychology", 9(3), 36-44.
[^10]: Karnewar, A., Vedaldi, A., Novotny, D., & Mitra, N. J. (2023). HOLODIFFUSION: Training a 3D Diffusion Model Using 2D Images. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 18423-18433.
This article synthesizes findings from academic research in computer vision, security, and legal analysis. Technical claims are supported by peer-reviewed publications. Legal interpretations acknowledge ongoing uncertainty and jurisdictional variation. Claims are presented with appropriate epistemic hedging where evidence is incomplete or contested.